
Distributed Locking With PostgreSQL and Spring Boot
Locks, PostgreSQL, Code , Examples and more.

Introduction
In modern microservices and high-traffic applications, multiple instances of your service often run concurrently. They may try to access the same resource—like refreshing a cache, updating a shared counter, or processing the same job—at the same time. Without coordination, this can lead to race conditions, redundant work, or even database overload.
This is where distributed locking comes in. A distributed lock ensures that only one service instance at a time can perform a critical operation, even if multiple servers are running in parallel.
We may think that we need a fancy distributed system like Redis, ZooKeeper, DynamoDB, or etcd to achieve this. Surprisingly, we can implement effective distributed locks using a single PostgreSQL instance that all our services share. Combined with Spring Boot, this provides a simple, robust solution without extra infrastructure.
Why Use Distributed Locks?
Consider a scenario: Spring Boot app caches user profiles from the database. When the cache entry expires, multiple requests hit at the same time. Without a lock:
All app instances may simultaneously fetch the same data from the DB
Database load spikes unexpectedly
Cache stampedes happen, slowing down all users
With a distributed lock:
Only one instance refreshes the cache
Others either wait or continue serving stale data
Database load is controlled, and performance stays consistent
PostgreSQL Advisory Locks
PostgreSQL provides advisory locks, which are lightweight application-level locks. Key properties:
Session-level: held until connection closes, can be blocking (
pg_advisory_lock) or non-blocking (pg_try_advisory_lock)Transaction-level: released at the end of the transaction, can be blocking (pg_advisory_xact_lock), can be non-blocking (pg_try_advisory_xact_lock)
These locks are global to all clients connecting to the same database, so multiple Spring Boot instances can coordinate using them.
Example SQL:
Blocking:

Non-blocking:

📢 📢 📢 Get actionable Java insights every week — from practical code tips to expert interview questions you can use today.
Join 3400+ subscribers and level up your Spring & backend skills with hand-crafted content — no fluff.
I want to offer an additional 40% discount ($ 18 per year) until January 31st.
Not convinced? Check out the details of the past work

Spring Boot Implementation
With Spring Boot, we can create a service class that provides lock and unlock method wrappers on top of SQL functions we saw earlier.
If we use a native query:
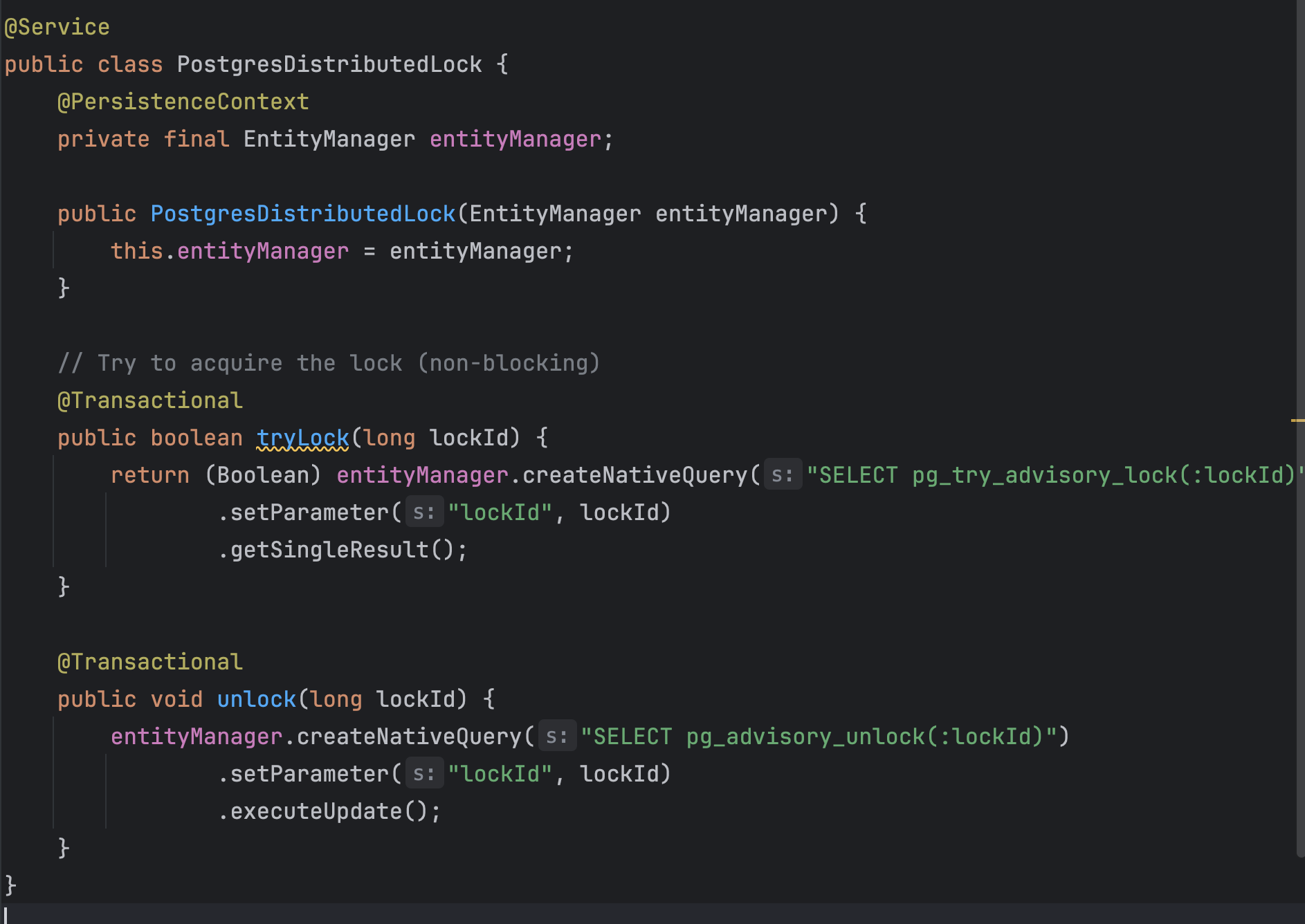
Using @Transactional ensures same connection, which is crucial for advisory locks.
We can also use Repository, with a native query:
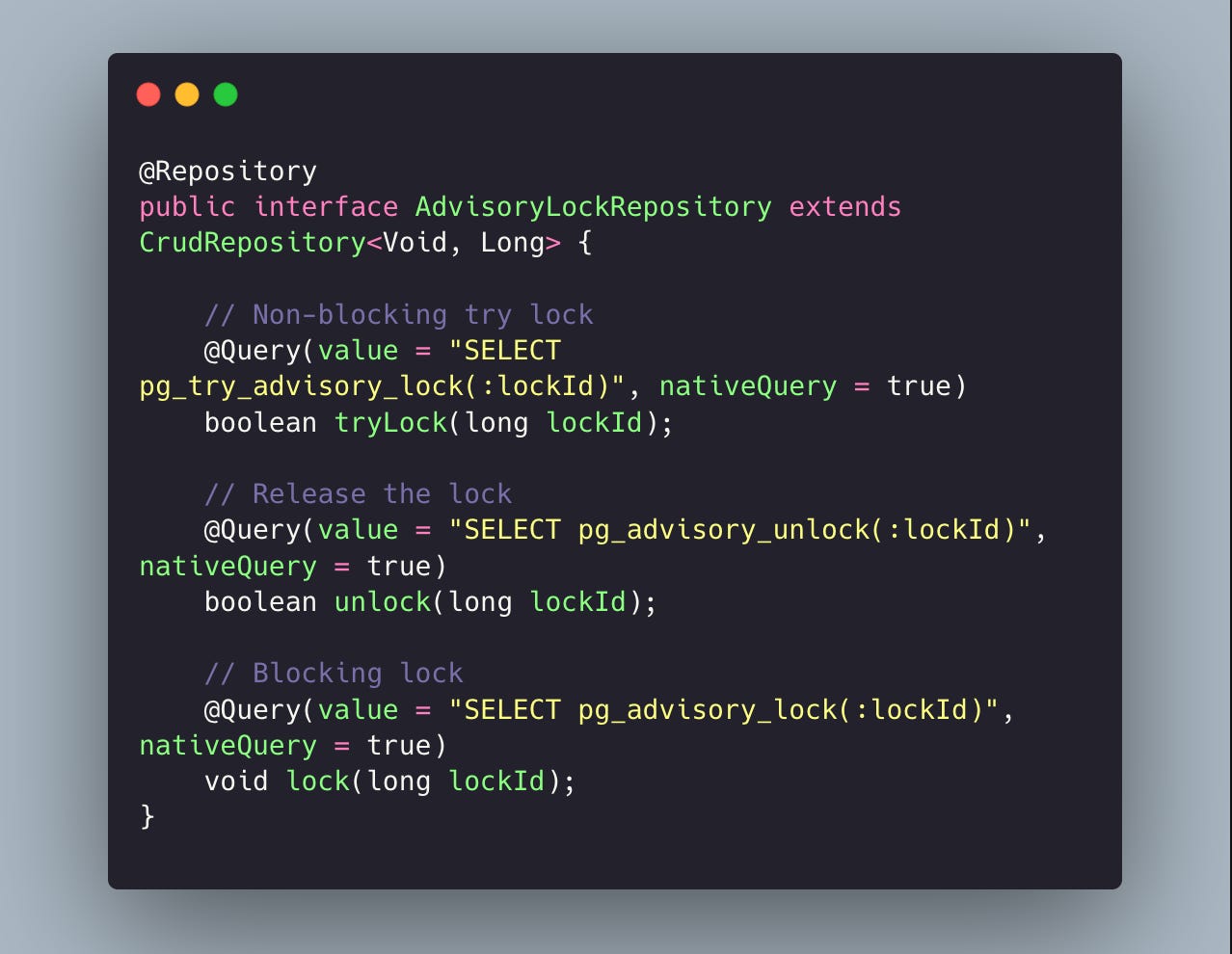
About lockId:
PostgreSQL advisory locks don’t know anything about your application.
They just lock a 64-bit integer (BIGINT) or two 32-bit integers.
You can choose any value, as long as all sessions that want the same lock use the same value.
PostgreSQL also allows:
SELECT pg_try_advisory_lock(key1, key2);
Useful if you want to combine two values (e.g., app ID + user ID) without generating a big number manually.
Example:
int appId = 123;
int userId = 456;
em.createNativeQuery("SELECT pg_try_advisory_lock(:key1, :key2)")
.setParameter("key1", appId)
.setParameter("key2", userId)
.getSingleResult();Service Layer
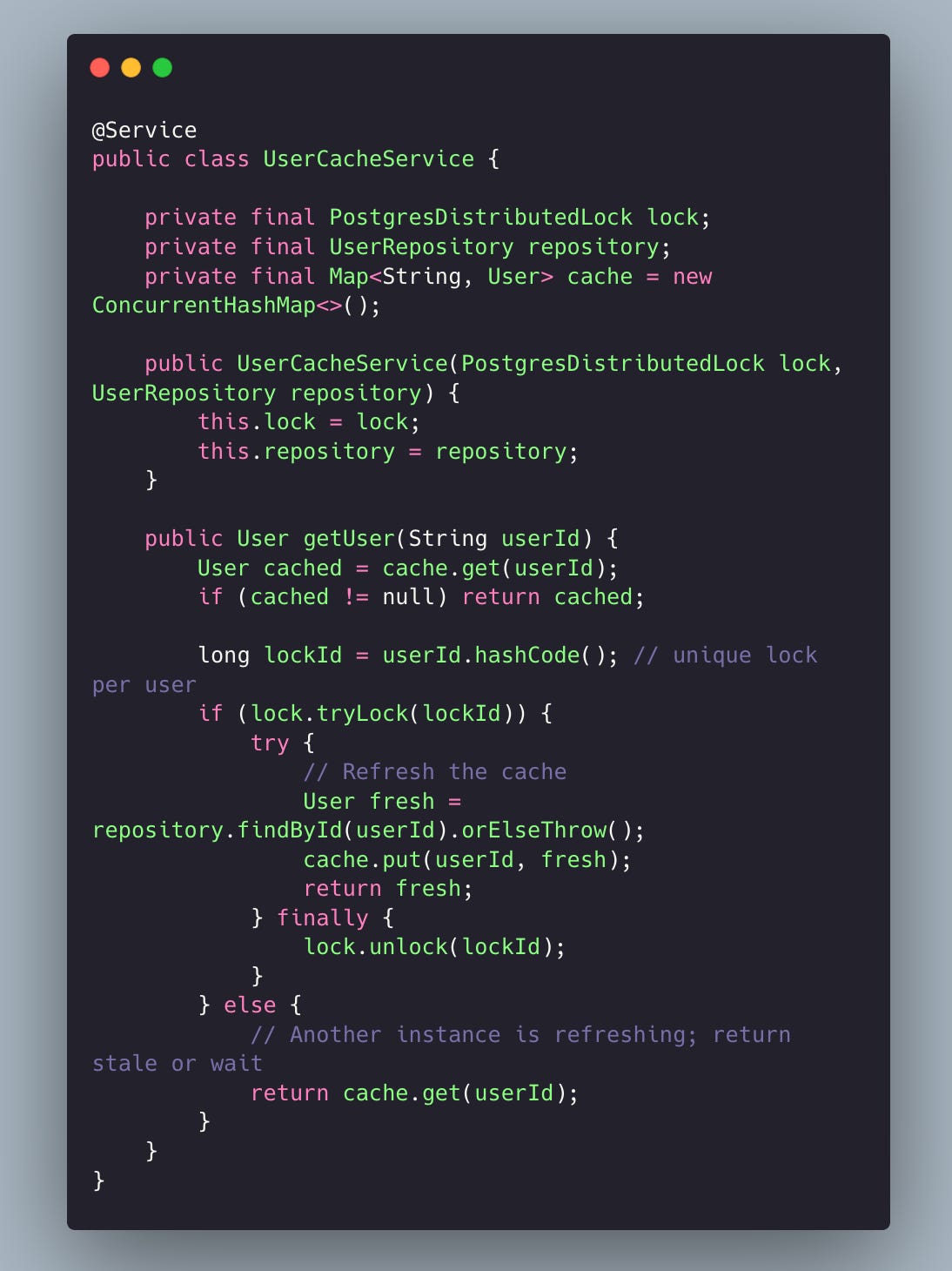
Benefits
No extra infrastructure needed: uses your existing PostgreSQL database
Safe across multiple Spring Boot instances
Prevents cache stampedes or duplicate work
Simple to implement and monitor
Caveats
The lock is tied to a single DB instance; if the database goes down, locking fails
Locks are connection-dependent: if the connection drops unexpectedly, the lock is released
Not suitable for multi-database or geo-distributed setups without extra coordination.
Conclusion
Distributed locks are essential for preventing race conditions in high-concurrency environments. Using PostgreSQL advisory locks with Spring Boot is a simple, effective, and production-ready approach. It’s especially handy for cache refreshes, job processing, or any shared resource where only one instance should act at a time.
With this pattern, Spring Boot apps stay fast, safe, and predictable, without introducing extra distributed systems into your stack.
📢 📢 📢 Get actionable Java insights every week — from practical code tips to expert interview questions you can use today.
Join 3400+ subscribers and level up your Spring & backend skills with hand-crafted content — no fluff.
I want to offer an additional 40% discount ($ 18 per year) until January 31st.
Not convinced? Check out the details of the past work

Helpful Resources (7)