
Spring Boot Interview Question — Building an Ad Impression Platform
Why raw event storage alone breaks at scale

Scenario
You are building an ad analytics platform similar to Google Ads or Meta Ads.
When an advertisement is rendered on a publisher page, your system records an impression.
Advertisers are billed based on impressions and clicks.
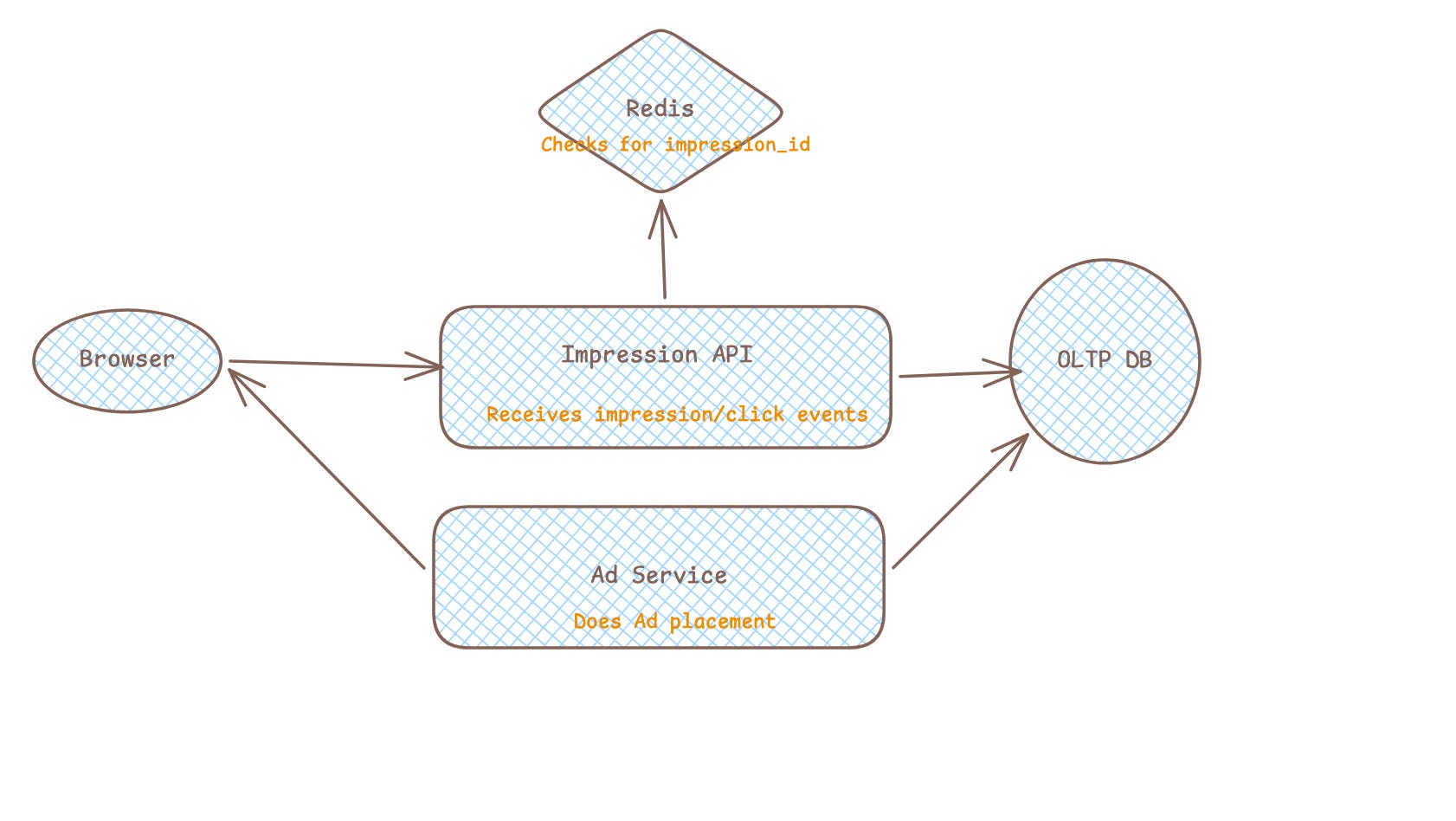
Current flow:
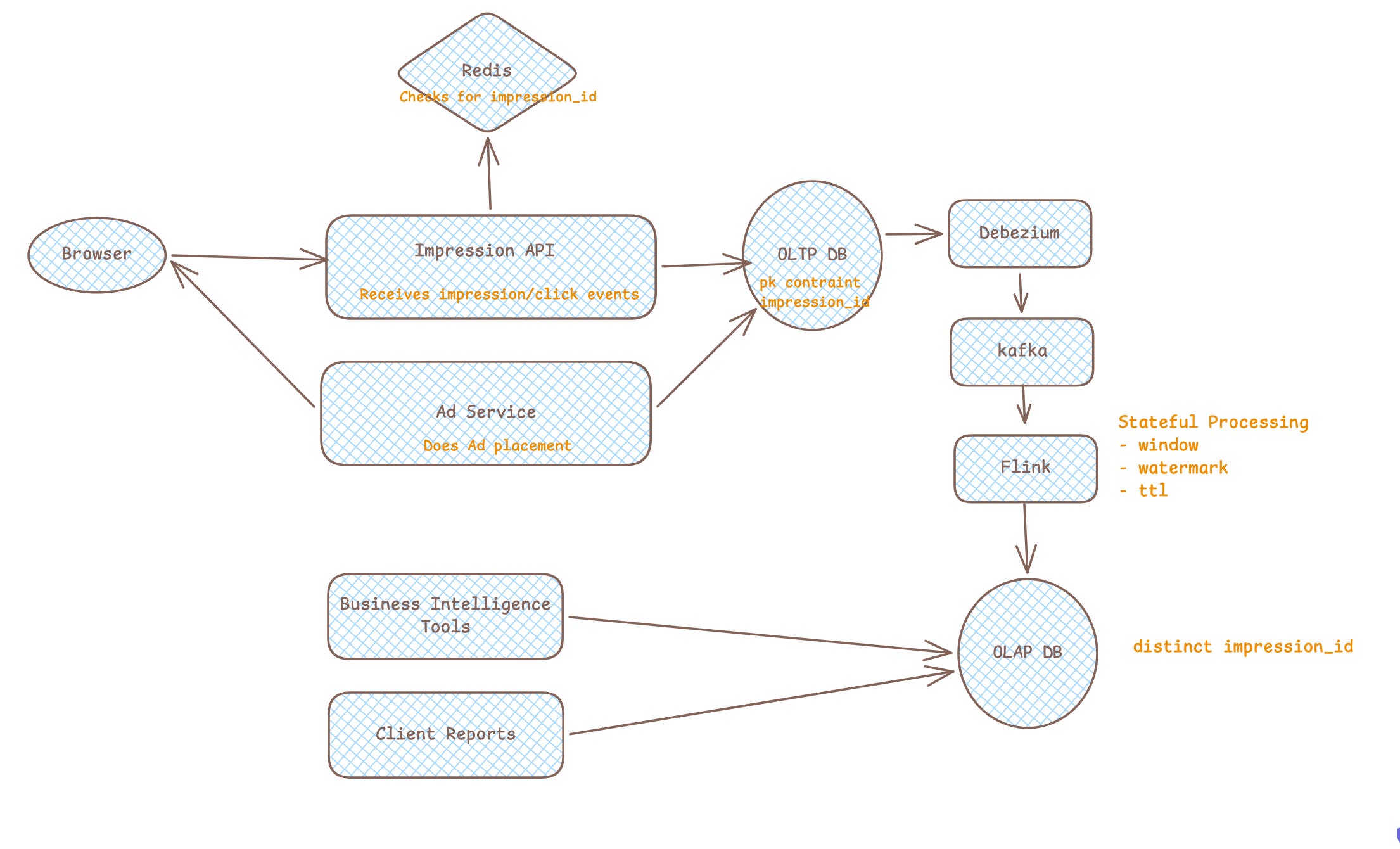
Browser
↓
Ad Service
↓
Impression API
↓
PostgreSQL
↓ (CDC)
Kafka
↓
Analytics/Billing SystemsWhen an ad is displayed, the frontend sends:
Payload:
{
"adId": "AD123",
"campaignId": "CMP9",
"userId": "USER42",
"timestamp": 1717000000
}The system records:
impression count
advertiser billing
campaign analytics
Production Incident
Advertisers complain:
We are being charged for duplicate impressions.
Investigation reveals:
mobile clients retry requests
network failures cause duplicate sends
CDN occasionally retries requests
Kafka consumers replay events during failures
Result:
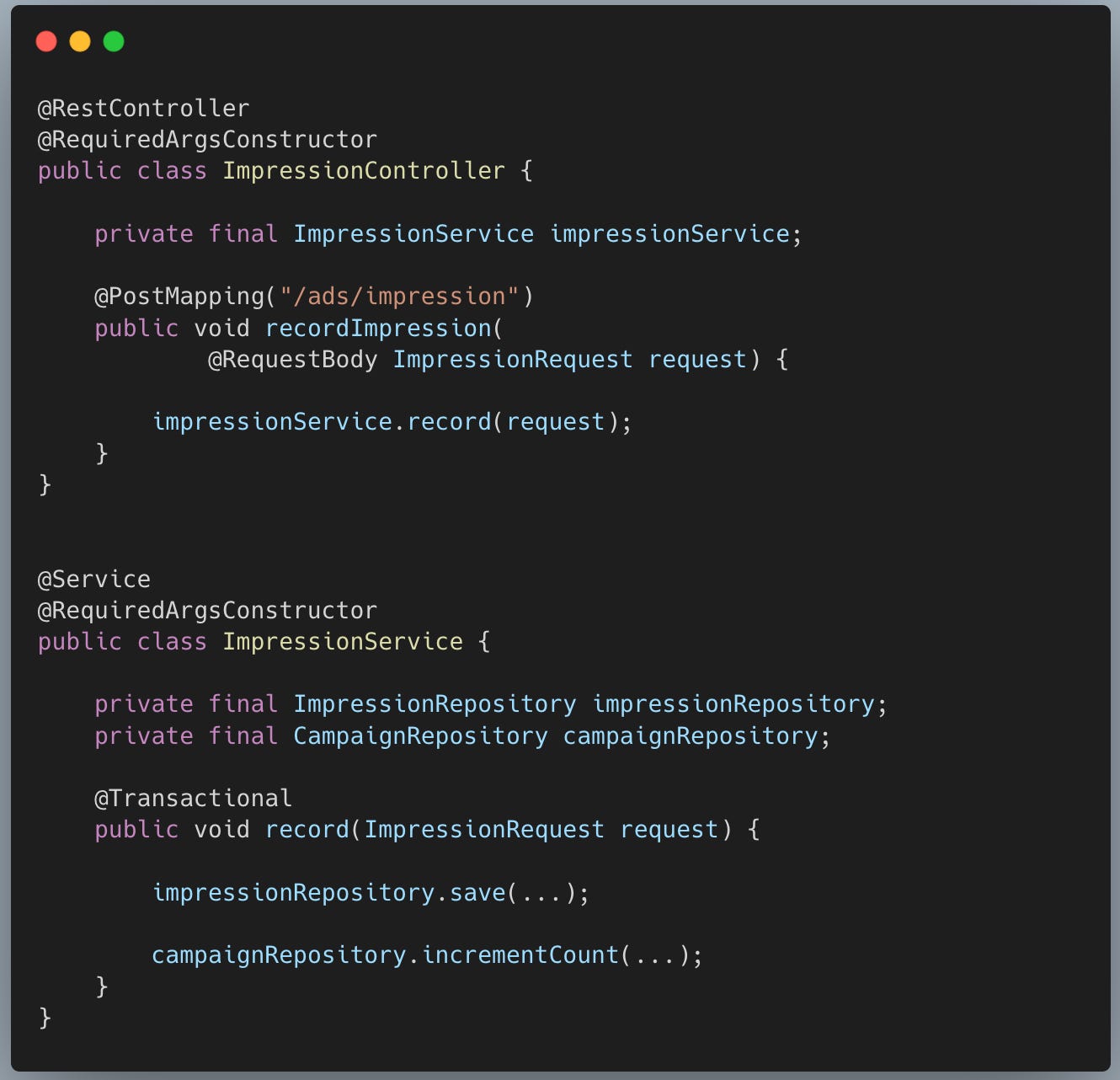
Same impression counted multiple times.API layer implementation
How would you redesign this system so that
Each impression is counted exactly once
Discuss the data model for that
It’s hard to enforce exactly once across
HTTP retries
DB writes
CDC
Kafka consumers
So we must define:
Single source of truth = PostgreSQL
Everything else = derived, replayable projectionsFor idempotency , we need a globally unique identifier such as impression_id , which should be generated by ad_service which is own by us.
This is:
created when ad is served
returned to browser
sent back in impression API
Then at the write layer, we can enforce constraint on the data model to keep the impression_id unique which should prevent any duplicate entry to our table.
Data model:
CREATE TABLE impressions (
impression_id UUID PRIMARY KEY,
ad_id UUID NOT NULL,
campaign_id UUID NOT NULL,
user_id UUID NOT NULL,
created_at TIMESTAMP NOT NULL
);The primary key enforces idempotency at DB level.
Now with this we at least ensure our source of truth do not contains duplicates.
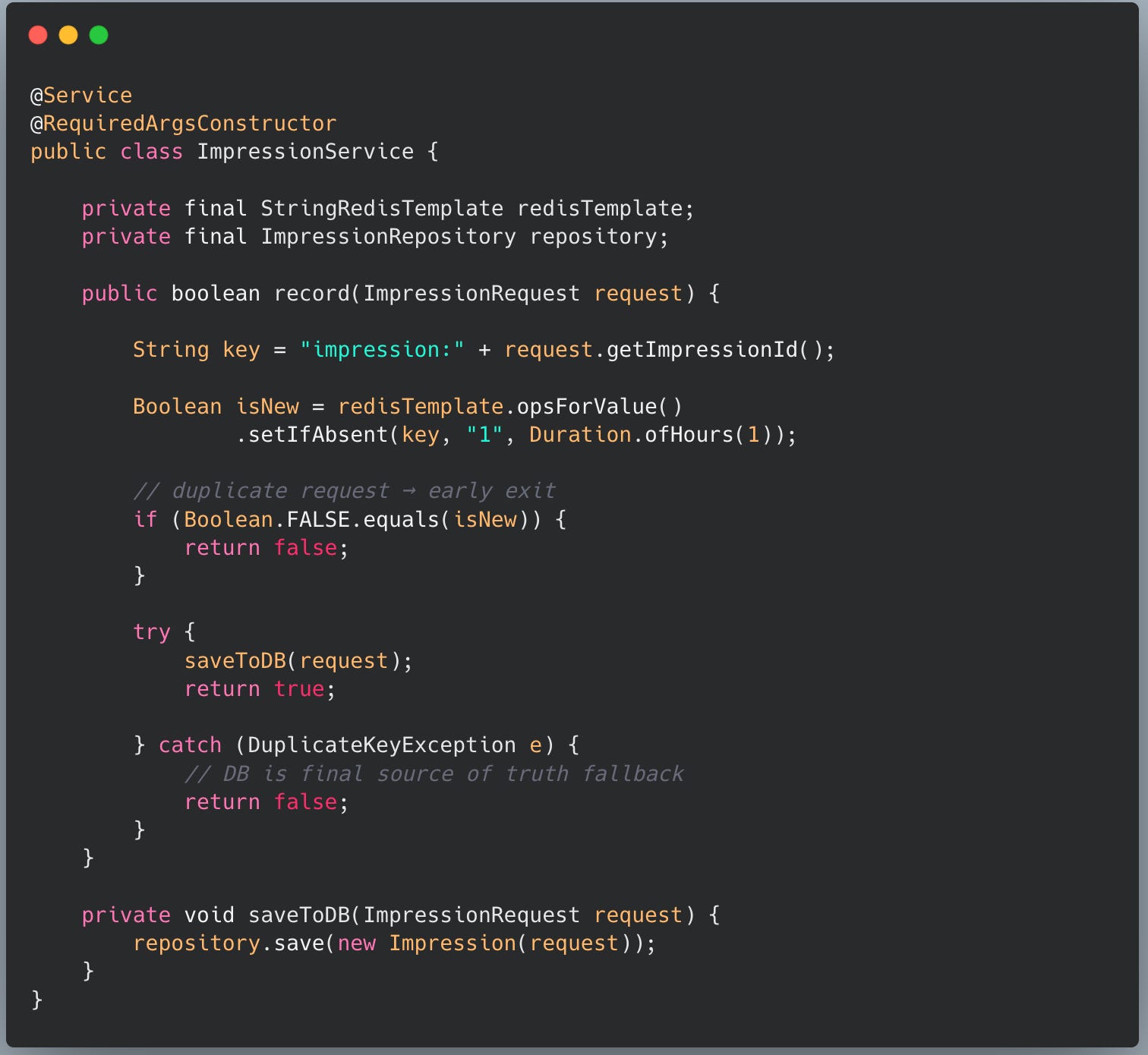
But with check at DB level pushes something very late in the stack which we can prevent early in request. We can have distributed cache like redis where we can store impression_id as key to check if they already exist in defined TTL and skip upon existence. This is good design and help us in two things:
Early termination of request
Prevent executing query on database that should be failing anyway.
High Level Design
📢 Get actionable Java and Spring Boot insights every week, including practical code tips and real-world, use-case-based interview questions, to help you level up your backend skills—join 7300+ subscribers for hand-crafted, no-fluff content.
First 100 paid subscribers will get the annual membership at $50/year forever that is ~ $4/mo ( 92 already converted to paid, 8 remaining)

Testimonials

How do you handle idempotency in stream processing + analytical layer to prevent double charging?
Kafka is treated as:
at-least-once event delivery systemSo duplicates may still occur. We do not rely on Kafka for correctness.
We should implement idempotency at stream processing and analytical layer.
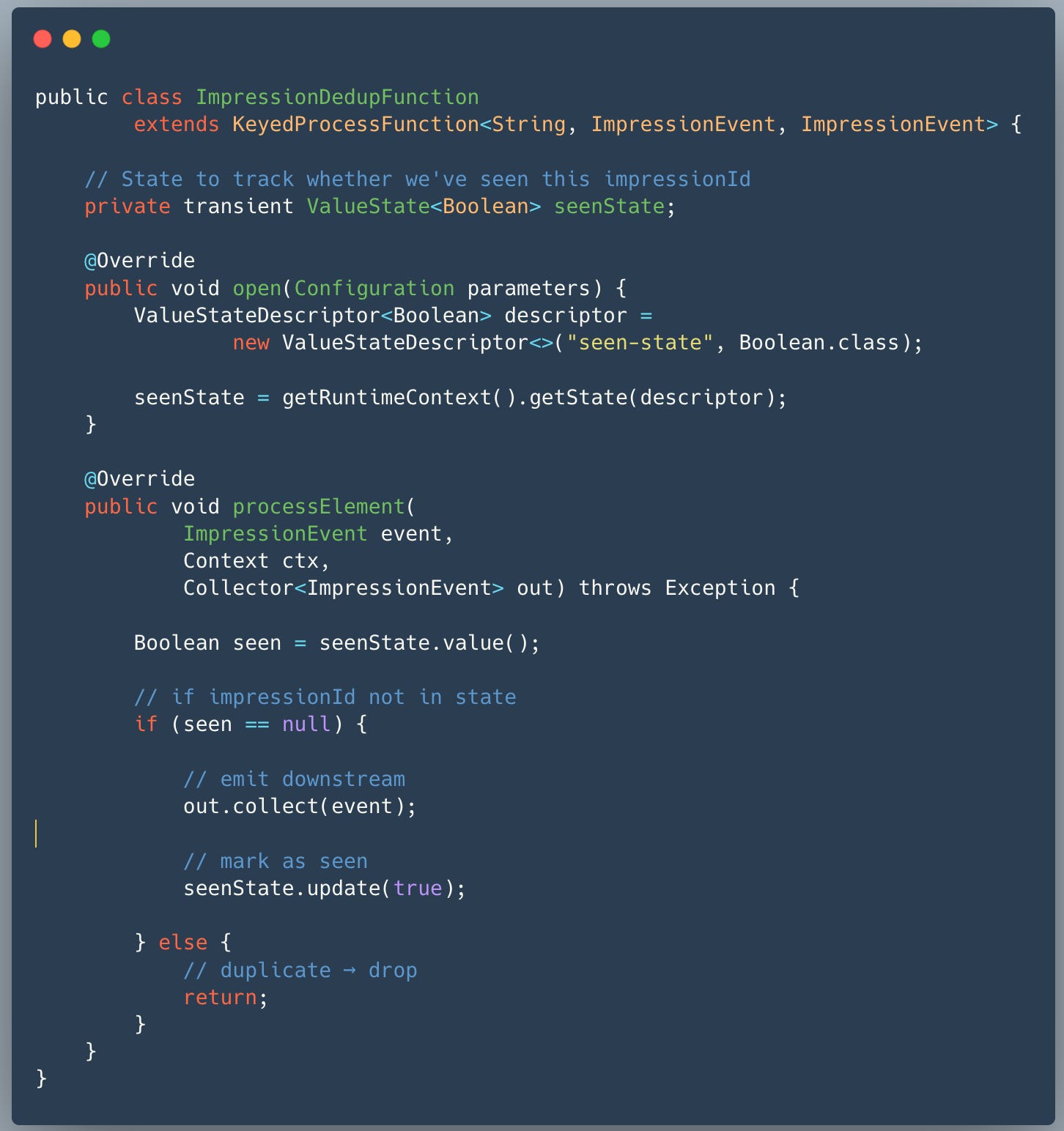
Stream processing layer like flink, beam can maintain store that can store see impression_id for defined TTL.
if impressionId not in state:
emit event downstream
mark as seen
else:
droppartitioned by impressionId (keyBy)
stored locally per worker
TTL applied (e.g., 1 hour)
So we get deduplicated event stream for analytics.
Flink Java implementation:
Even idempotency at this layer cannot guarantee or prevent duplicates fully. We can still have worker failed, retry outside of TTL or late arrival data which essentially skips seen impression_id. Hence we should also make sure our analytical query perfrom uniqness/distinct count over impression_id when computing the metrics.
SELECT
campaign_id,
COUNT(DISTINCT impression_id)
FROM impressions
GROUP BY campaign_id;Why not just store raw events and compute everything using SQL in Analytical Database like BigQuery?
We could store:
impression events → BigQuery (raw table)Then compute everything:
SELECT campaign_id, COUNT(DISTINCT impression_id)
FROM impressions
GROUP BY campaign_id;So functionally It works.
Query cost becomes explosive
In systems like Google BigQuery:
cost is based on bytes scanned
raw event tables grow to billions–trillions of rows
So every query becomes:
scan massive dataset → group → aggregateEven simple dashboards become expensive and unpredictable.
Repeated computation of the same logic
Every team writes:
CTR calculation
impression counting
dedup logic
filtering rules
Example:
COUNT(*)
COUNT(DISTINCT impression_id)
filtered COUNT(*)So the same business logic is recomputed everywhere.
Latency for dashboards
Raw computation means:
scan TBs → aggregate → return resultThis is too slow for:
real-time dashboards
advertiser portals
fraud monitoring
These issues reveals deeper org level inefficiency.
Raw event querying pushes all complexity to query time:
storage is simple
computation is repeated everywhereThis does not scale organizationally.
Overall Design
Thats all for this week friends! Thanks for reading this far. If you liked it please share with your network.
Happy Coding 🚀
Suraj
Subscribe | Sponsor us | LinkedIn | Twitter