
Spring Boot Interview Question – Improve API Latency

Scenario
You are working on a Spring Boot API that returns large JSON responses (100 KB – 2 MB). Your Spring Boot API serves large JSON responses (100 KB – 2 MB).
Recently, partners have reported that API response times have increased.
Seems like there was a new change made to the endpoint that shot up the latency. The changes are following:
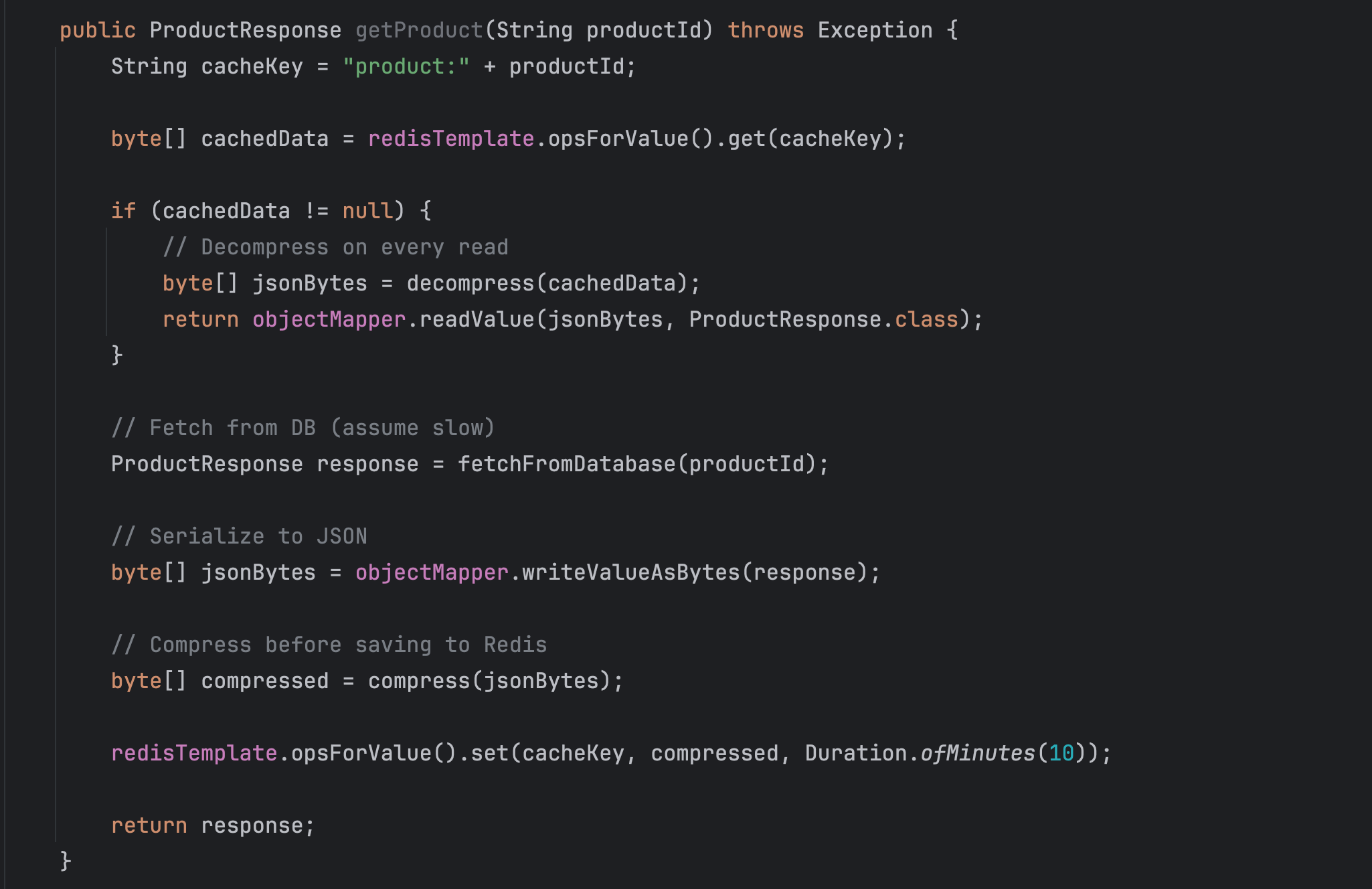
Some facts about the system:
Redis is distributed / clustered
CPU on app servers is high
API latency at P95/P99 is increasing
Cache reads happen very frequently
📢 Get actionable Java/Spring Boot insights every week — from practical code tips to real-world use-case based interview questions.
Join 5000+ subscribers and level up your Spring & backend skills with hand-crafted content — no fluff.
First 100 paid subscribers will get the annual membership at $50/year ( 60 already converted to paid, 40 remaining )

Not convinced? Check out the details of the past work
What will be your initial steps for the investigation?
At first we will look at the observability tool and understand the latency graph of the endpoint in question. We should compare this latency over the last month and confirm if there is a latency increase.
Once we confirm that the latency has shot up, we should check if there are recent changes committed to this endpoint in GitHub/Version control. This reveals the changes to the code.
Once we confirm the latency has shot up over last week, we will look at the detailed trace of the request and investigate the flamegraph.
example:
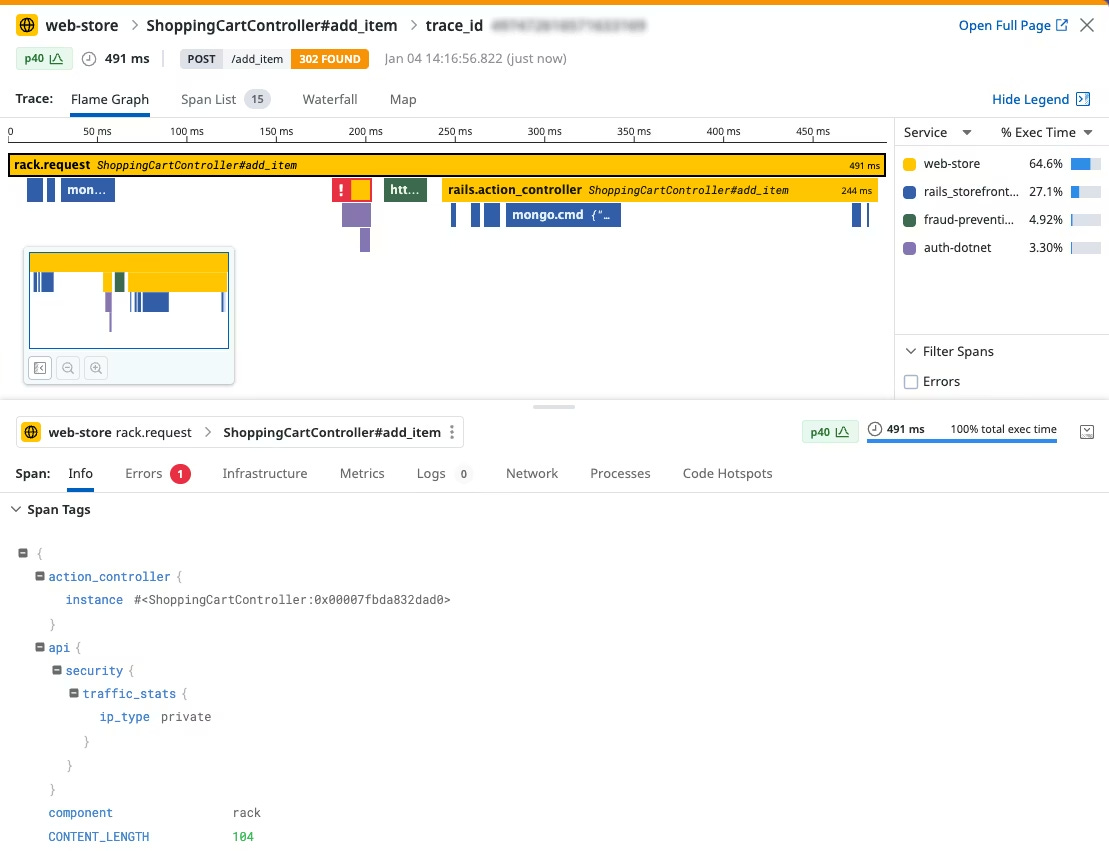
After spending time studying the flamegraph for over a month, it should reveal that the cache step has increased the time it generally takes to finish.
Alright, if you look at the code, what are your thoughts on improving latency? Would you keep compression? Why or why not?
Key Observation from system facts:
CPU is the bottleneck; memory is cheap
Compression + decompression on every read is costly
Redis is not the limiting factor; with a distributed and clustered environment, we can scale the memory.
Frequent reads amplify CPU usage
Seems like the current compression strategy hurts performance more than it helps.
Recommended Optimizations:
Disable Compression
Store raw JSON bytes in Redis
Avoid CPU overhead on every read
Simple and fastest approach.
redisTemplate.opsForValue().set(cacheKey, jsonBytes, Duration.ofMinutes(10));
return response;Some tradeoffs:
Increased memory
increase in network bandwidth since we are sending raw bytes over the network for the cluster. But we can avoid that by keeping this cache local to the app, but that would endup not being available for other apps until they get their own cache initialized.
Compress Once, Cache Both Versions
If compression is required:
Compress only once on write
Store compressed version for client, raw version for server
Avoid recompressing on every read
Implications:
Writing two keys doubles the network traffic between the app server and the Redis cluster
CPU saved on app servers comes at the cost of extra memory + write network bandwidth
Use Fast Compression Algorithms if Needed
Snappy, LZ4, ZSTD (fast mode) → low CPU
Avoid GZIP max compression for frequently-read keys
Alright, so once you implement the above suggestion, what metrics will you track to measure the success?
P95 / P99 latency
CPU usage per instance
Redis hit rate
Network usage between app servers and the cluster
Write latency in Redis cluster (if storing both keys)
Throughput (req/sec)
Do you have any additional suggestions?
We can cache pre-serialized JSON to avoid ObjectMapper overhead
Consider streaming for very large objects instead of transferring large objects.
We can benchmark different compression algorithms and decide on which works out better for our scenario.
📚 Helpful Resources (7)
44+ Real-World Use Case-Based Java/Spring Boot Interview Questions
Everything Bundle (Java + Spring Boot + SQL Interview + Certification)
I think that it would be a good idea, in the case of a cache miss, to start a background thread to compress the data and update the Redis cache, and return the response immediately instead of waiting for the compression and cache update.
i really liked this. im currently junior but these things really catches my interest