
Spring Data Interview Question : Efficient Keyset Pagination with Spring Data WindowIterator
Pagination, Optimization, Concept, Code Examples and more ...

Scenario
You’re building a Spring Boot API to fetch comments for a post.
The table has tens of millions of rows, and users can scroll deeply into the history.
Initial Implementation:
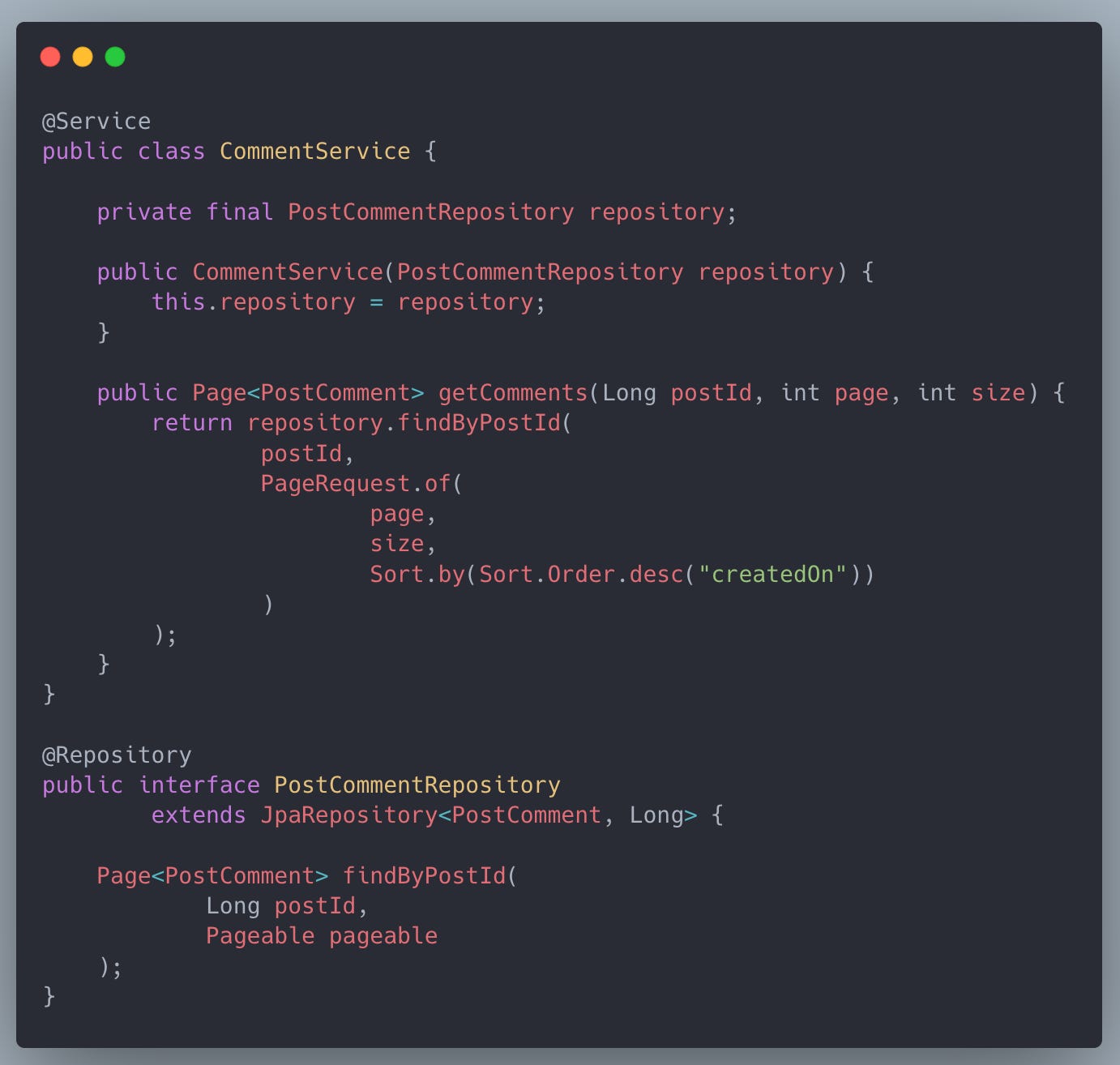
Problem Observed in Production
As users scroll deeper:
Queries slow down dramatically
DB CPU rises
Response times become inconsistent
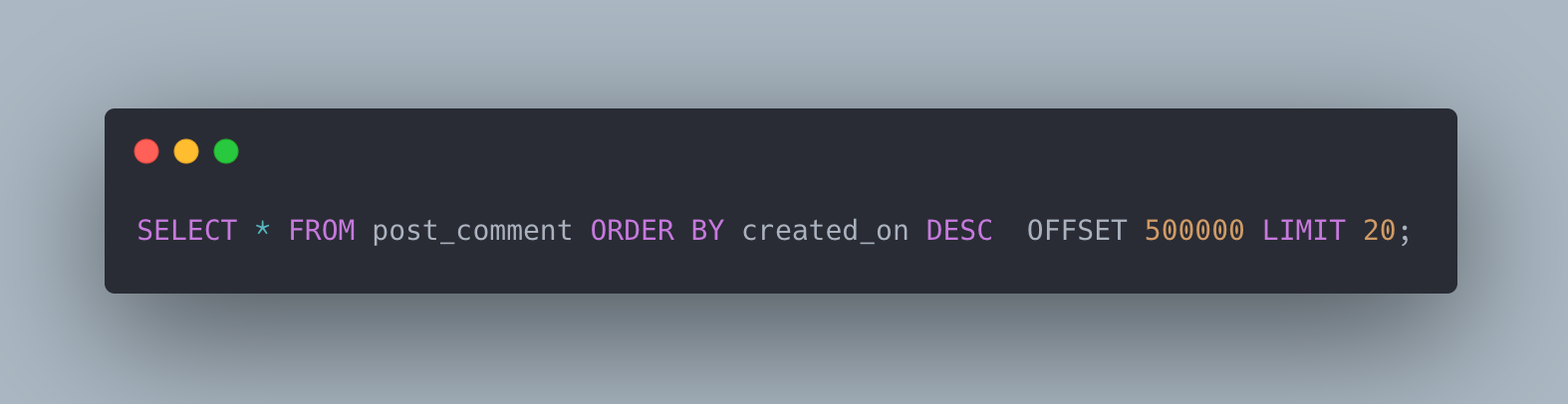
Upon investigation, we found that the actual executed query is somewhat like below:
Why offset pagination is inefficient
Offset pagination becomes inefficient because the database must scan and discard rows before returning the requested page.
What OFFSET actually does is:
SELECT *
FROM post_comment
ORDER BY created_on DESC
OFFSET 100000 LIMIT 20;The database does not jump to row 100000.
Instead it:
Reads rows in sorted order
Counts up to 100000
Discards them
Returns the next 20
So it still processes 100020 rows to serve that request.
Why does performance worsen with deeper pages?
page 1 → 20 rows scanned
page 100 → 2000 rows scanned
page 10000 → 200000 rows scanned
page 100000 → 1M rows scannedThis leads to:
More disk reads
More CPU sorting work
Larger temporary buffers
Higher query latency
So latency increases linearly with page depth.
📢 Get actionable Java/Spring Boot insights every week — from practical code tips to real-world use-case based interview questions.
Join 6200+ subscribers and level up your Spring & backend skills with hand-crafted content — no fluff.
🎯 Early Supporter Offer
The first 100 paid subscribers get the annual membership at $50/year.
👉 70 already joined — only 30 spots left.

Not convinced? Check out the details of the past work
So If offset does not scale well, What do you think we should use to improve the performance at scale?
Standard production solution is keyset pagination (a.k.a. seek pagination).
Instead of saying:
“Give me page 500”
We say:
“Give me rows after this last seen record”
This lets the database jump directly to the next rows using the index, instead of scanning and discarding earlier ones.
Example:
SELECT *
FROM post_comment
ORDER BY created_on DESC, id DESC
OFFSET 100000 LIMIT 20;We do this:
SELECT *
FROM post_comment
WHERE (created_on, id) < (:lastCreatedOn, :lastId)
ORDER BY created_on DESC, id DESC
LIMIT 20;Now the DB:
Uses the index to seek to the position
Reads only the next 20 rows
No scanning or discarding needed
Performance becomes O(page_size) instead of O(offset).
Why this scales
Keyset pagination:
Uses index seeks instead of scans
Has constant query cost regardless of page depth
Works well with millions of rows
Avoids duplicate/shifted results during inserts
This is why large systems use it for:
Social feeds
Comments
Activity timelines
Messaging history
How will you refactor the code to use KeySet based pagination ?
@Service
public class CommentService {
private final PostCommentRepository repository;
public CommentService(PostCommentRepository repository) {
this.repository = repository;
}
public List<PostComment> streamAllComments(int batchSize) {
WindowIterator<PostComment> iterator =
WindowIterator.of(position ->
repository.findAllBy(
PageRequest.of(
0,
batchSize,
Sort.by(
Sort.Order.desc("createdOn"),
Sort.Order.desc("id")
)
),
position
)
).startingAt(ScrollPosition.keyset());
List<PostComment> results = new ArrayList<>();
iterator.forEachRemaining(results::add);
return results;
}
}What this does:
Fetches rows in windows (batches)
Uses keyset pagination automatically
Keeps memory usage small
No OFFSET anywhere
No manual cursor management
Endpoint Example
@RestController
@RequestMapping("/comments")
public class CommentController {
private final CommentService service;
public CommentController(CommentService service) {
this.service = service;
}
@GetMapping("/stream")
public List<PostComment> streamAll() {
return service.streamAllComments(100);
}
}This endpoint:
Iterates over millions of rows safely
Loads only small windows at a time
Uses indexed seeks under the hood
Seems like we rely on sorting of the column on which we do filter. What if don’t have index on that column?
Keyset pagination relies on seeking directly to a position instead of scanning rows.
The query uses
WHERE (created_on, id) < (:lastCreatedOn, :lastId)The database can only efficiently jump to this position if there’s an index on the columns used in the WHERE + ORDER BY clause.
Without it:
The database has to scan all rows to evaluate the condition
Performance degrades to the same problem as OFFSET, especially on large tables
What if we need to access random page ? Will Keyset pagination help us ?
keyset pagination (also called cursor-based pagination) does not support random page access, and this is one of its fundamental trade-offs.
Keyset pagination (seek pagination):
Fetches the next page based on the last row’s sort values (
created_on,id)Works extremely efficiently even with millions of rows
Cannot jump to an arbitrary page number directly
Designed for infinite scroll or streaming
Problem with random pages:
Client asks for page 1000
Keyset needs a “cursor” pointing to the start of that page
Without storing all cursors, the database has no shortcut → cannot jump
OFFSET could work here, but at scale it’s slow
if Random Page Access is Required
We can use hybrid approach:
Use keyset for scrolling / most users
Allow OFFSET only for rare “jump to page” requests
Precompute cursors
Store mapping of page numbers → keyset values
Works for reporting dashboards, but adds storage/complexity
📚 Helpful Resources (5)
Subscribe | Sponsor us | LinkedIn | Twitter
Happy Coding 🚀
Suraj