
Spring Data Interview Question - Orders API Suddenly Slows Down
Rethinking high-update systems ...

📢 I started another publication that focuses on SQL and Database & covers Daily SQL question. If it interests you Consider subscribing
Scenario
You are a backend engineer on a Spring Boot microservice managing customer orders. The service uses PostgreSQL.
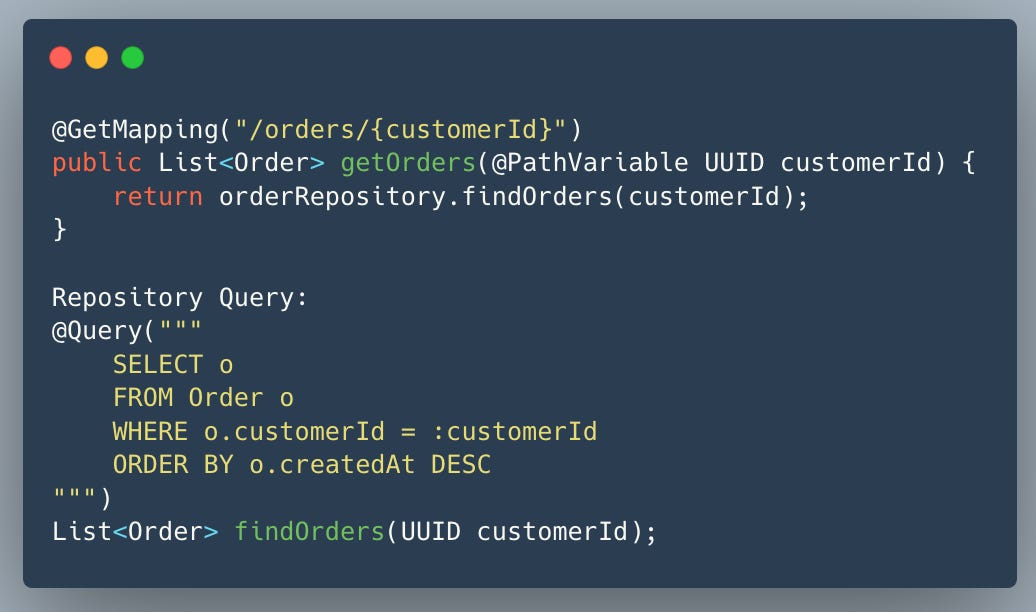
Problem
The API has always been fast (<20ms) for a table with 8,000 orders.
Suddenly, it takes 1.5–2 seconds.
Metrics: CPU, memory, and DB connections are normal.
PostgreSQL statistics show:
SELECT relname, n_live_tup, n_dead_tup
FROM pg_stat_user_tables
WHERE relname = 'orders';relname | n_live_tup | n_dead_tup
orders | 8,000 | 4,000,000
Why does PostgreSQL accumulate millions of dead rows even though the table has only 8,000 active orders?
This is classic MVCC (multi view concurrency control) issue.Each row version is immutable once written. When we UPDATE or DELETE a row:
PostgreSQL doesn’t overwrite it.
It creates a new version of the row.
The old version becomes a dead row (aka obsolete tuple).
Even though there are only 8,000 active orders, the table has millions of dead rows because:
Frequent updates:
Orders often change status (
pending → shipped → delivered → canceled).Every update generates a new row version; the old one becomes dead.
Soft deletes:
If we mark orders as inactive instead of deleting, and then later update, MVCC creates new row versions.
Long-running transactions:
Dead rows aren’t removed until all transactions that could see them are finished.
Old snapshots prevent immediate cleanup.
Queries (even with an index) sometimes need to visit dead rows:
Sequential scans touch the whole heap.
Index scans still may check the heap to confirm visibility of each row.
The more dead rows, the slower queries become.
Example: 8,000 live rows but 4,000,000 dead rows → the database may scan or filter through millions of tuples, inflating query time.
Join 6,500+ subscribers and get actionable Java/Spring Boot insights every week — from practical code tips to real-world, use-case-based interview questions — and level up your Spring & backend skills with hand-crafted content, no fluff.

First 100 paid subscribers will get the annual membership at $50/year forever, that is ~ $4/mo ( 71 already converted to paid, 29 remaining)
What are some of the strategies we can implement to avoid this problem?
To avoid scanning dead rows unnecessarily in PostgreSQL when using Spring Data JPA, the goal is to:
Select only the columns we need (use a projection instead of
SELECT *) : avoids touching extra heap pages.Use indexes effectively: queries should leverage an index on
(customer_id, created_at).Apply pagination if possible: prevents scanning the entire table for a single request.
These steps potentially could help but even with projections, indexes, and pagination, high-update tables can still create performance problems in PostgreSQL due to MVCC and dead rows.
Batch updates (If possible)
Instead of updating rows individually, batch updates reduce the number of new versions created.
Example: mark 1000 orders at a time instead of one-by-one.
Use append-only / immutable patterns
Instead of updating rows in place, insert a new row for each status change and record timestamp of each insert
Queries then filter only latest timestamp, reducing dead row impact.
Partitioning
Split
ordersinto customer-based or date-based partitions. customer based maybe result in many active partition and also can have hot partition due single high customer.Having time based partition basically give us opportunity to detach the old timestamp partition and keep the read query to small number of active partition upto certain days.
Autovacuum tuning
Increase autovacuum aggressiveness for high-update tables:
ALTER TABLE orders
SET (autovacuum_vacuum_scale_factor = 0.05, -- vacuum when 5% rows are dead
autovacuum_vacuum_threshold = 500);Vacuum runs more frequently, dead rows removed sooner.
What do you think about using other database like DynamoDB for this use case?
Using DynamoDB for a high-update, order-tracking table has some clear trade-offs compared to PostgreSQL.
Pros:
No MVCC bloat
Unlike PostgreSQL, DynamoDB doesn’t create dead rows for updates. Each write overwrites the existing item (by primary key), so we avoid table bloat and slow queries caused by millions of dead rows.
Predictable write performance
Throughput scales with provisioned capacity or on-demand mode. Writes and reads are predictable even under heavy load.
Natural append-only design with versioned keys
We can design our table with a composite key like
PK = ORDER#123, SK = TIMESTAMPto store history. Latest versions can be queried efficiently using sort keys.
Simpler high-write patterns
We don’t need to batch updates or carefully tune autovacuum. Insert-only or overwrite operations are cheap and avoid PostgreSQL’s dead row overhead.
Cons:
Query flexibility is limited
Unlike SQL, we can’t easily do complex queries like “latest version per customer with filters” unless we plan our keys and indexes carefully.
Manual history management
If we want audit history, we need an append-only pattern with a timestamp or version number. DynamoDB doesn’t track history automatically.
Indexing / filtering limitations
Secondary indexes exist but aren’t as flexible as PostgreSQL’s multi-column indexes and rich query planner.
Transaction constraints
Multi-item ACID transactions exist but are more limited than a relational database for complex operations.
In summary:
DynamoDB is actually well-suited for high-update workloads because updates overwrite items instead of creating new versions like PostgreSQL’s MVCC, so there’s no dead row buildup or vacuum overhead. It also supports append-only patterns if we need history, but the key trade-off is reduced query flexibility compared to SQL.
That’s it for this one friends! If you like this please help sharing this in your network.
Subscribe | Sponsor us | LinkedIn | Twitter
Happy Coding 🚀
Suraj